编程语言的开发者在实现完整版FB之前,可以先实现基于'字节集数组'作为参数的FBmake版本函数,该函数仅仅只是一个最简化封包实现的过渡,来测试各自字节数据的参数在封包后的完整字节集存储分布情况
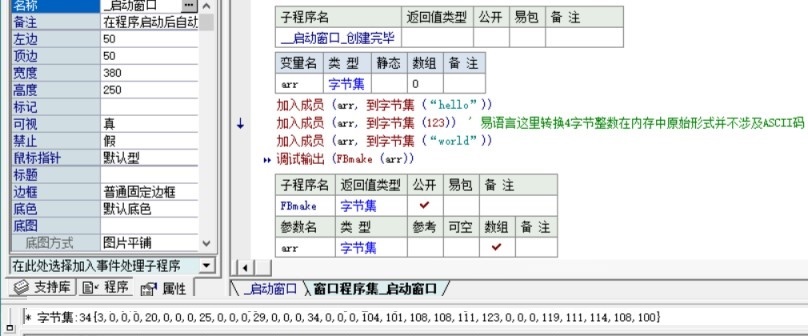
字节集:34
{3,0,0,0,20,0,0,0,25,0,0,0,29,0,0,0,34,0,0,0,104,101,108,108,111,123,0,0,0,119,111,114,108,100}
/*假定封包中有两个参数(int,
short)*/FB:{
header:{
0:
参数个数(4字节) 4:
第1个参数(所在起始封包)相对位置(4字节) 8: 第2个参数相对位置(4字节) 12:
表示结束尾的相对位置(4字节)
}
16: 第1个参数值(这里int为4字节) 20: 第2个参数值(这里short为2字节)}这里先给个建议(尽管不是必须的):
编程语言的开发者在实现完整版FB之前,可以先实现基于'字节集数组'作为参数的FBmake版本函数,该函数仅仅只是一个最简化封包实现的过渡,来测试各自字节数据的参数在封包后的完整字节集存储分布情况
字节集:34
{3,0,0,0,20,0,0,0,25,0,0,0,29,0,0,0,34,0,0,0,104,101,108,108,111,123,0,0,0,119,111,114,108,100}
在计算机中无论是有符号还是无符号整型,其内存的存储结构都是原则上等价一致的,
比如在C语言中将-1分别存储为char和uchar它在内存底层都是8位容器的全1
此外对char容器存入130这种超过了自身容器半数的有符号数与uchar的内存模型也是一致的
也就是说重点不在于字面量所给的数它会对应于有符号或无符号的同等类型下的影响(因为字面量给的值通常认为不会超过所给容器最大无符号上限的值,否则会溢出则无意义,这也是较多现代脚本语言选用8字节作为基本整型存储的依据——当然也有可能使用变长形式存储,最大不会超过8字节),而在于整型值的解析上!
原先<1.2>我们说过对于PHP这种无法用精确类型表示整型的脚本语言,我们的方案默认是将其存储为有符号的4字节整数(尽管PHP内部是把它存储为8字节整数了),如下例子展示:
那如果我就是要把整型的存储换为其他字节该怎么办?
我们直接构造该字节集就可以了,在PHP中使用pack()函数可以进行构造——基于某一参数为原型构造相关类型的二进制数据(注:PHP中String与Bytes的实现是等价的);
下面摘抄自FB.php文件中的实现:
应用例子:
PS:之前我们讨论分析过有符号跟无符号整型的存储从底层二进制来看都是一样的,所以尽管PHP中有大写版的"C、S、L"可以作为无符号类型,但它是适用于解析端的,跟这里搞存储上其实没有区别。
然后说说整型的解析方面,
首先由于PHP底层用于8字节存储,故所有比它位数之下的类型都能完美表示;
在封包的存储过程中由于没有定制任何关于表示确切类型的存储(仅有大小),则读取后的解析是无法判别该数究竟表示为有符号还是无符号,而如果编程语言本身支持确切类型容器了则按照这个类型去解析即可,那对于PHP该怎么搞个方案来实现呢?
先看看例子:
在FB.php中我的实现是:
只需提供两个值的标签、预先赋值给要输出的引用变量可确定用户究竟想解析为有符号还是无符号,而容器大小本身由封包数据得知,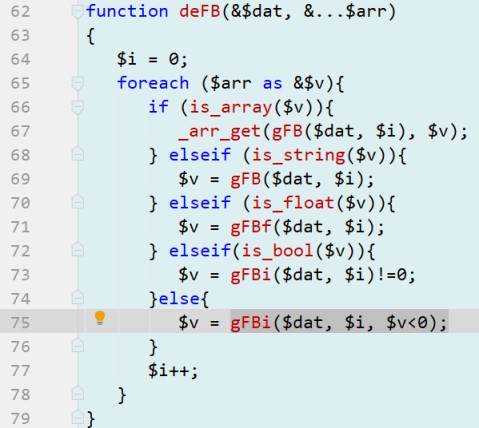

PS:如果是有符号默认按l、c、s、q来解析,如果是无符号则把解析类型改为大写也就是L、C、S、Q,
另外无符号的64位(Q)我也测了,PHP内部确实是不支持的——只不过人家手册上故意写只为了对称示意
下面几个例子可以充分证明不支持无符号64位:
最后顺带说说PHP中的浮点数:
虽然手册中有提到is_float、is_double,但官方说它们是同义词,
也就是PHP内部默认是以double作为对小数类型存储的,跟我们封包存储整型同理,我这里单独给出了f32函数来进行转换让它内部直接按该字节集进行存储即可。
而解析方面,由于浮点型要么是float要么是double,故只需给出其大小就能够完全区分这两了(大小本身在封包中就已知),且在PHP中也有单独pack类型'f'和'd'进行解析。
对绝大部分语言而言文本型和字节集基本都是分家的,比如C语言习惯性用\0作为字符串的终止符(只需提供该内存首地址即可知道字符串的长度),若要表示字节集类型则需要缓冲区中提供长度这么一个字段(一般是首地址的前4个字节),而PHP中String和Bytes的实现则是完全一致的(它均用字节集的实现方案且它本身也支持按二进制的原始内容进行存储和处理),
但其他语言比如python、js这种,文本型和字节集是严格分家的,我们这里不过多讨论它们内部的实现,但凡是数据最终一定能够导出为字节集,关键是我们要约定文本型这种要统一好编码(这样在双方解码为自身字符串类型的时候才能有一个依据);
在FB存储方案中,通通把这两都视为字节集按照<3.1
基本内存模型>进行参数封包,在文本型中建议应当本身统一的编码是UTF-8,然后导出字节集(结尾不强制需或无需空终止)进行存档;
而在FB解析时,只需根据用户投入的变量类型判别本次解包的参数应当是本语言的文本型还是字节集了!
比如下面易语言的封包和解封包实现:
| 子程序名 | 返回值类型 | 公开 | 备 注 | ||
| __启动窗口_创建完毕 | |||||
| 变量名 | 类 型 | 静态 | 数组 | 备 注 | ||
| fb | 字节集 | |||||
| a | 文本型 | |||||
| b | 字节集 | |||||
而PHP中由于String和Bytes不分家,则只需给出声明是字符串即可
而在Python中有b""的则表示是bytes类型,没b的则是普通字符串类型(该类型不能直接处理二进制)
对于可知常量大小的基本数据类型的数组而言,实际上无需按照FB原本的头部是偏移位置方案去搞存储(否则太浪费空间了),我们只需用1字节去约定好当前封包的数组是何种类型的就可以了,下面是封包例子
数组这一总体在封包层面还是按照<3.1 基本内存模型>去进行的没有问题,而arr数组单独作为一个序列化后的整体作为一个字节集形式存入FB的一个参数中(其数据类型由数组的第一个成员来确定),而其单个数组内部的序列化存储格式也很简单:
若对于不可知常量大小的类型(如String、Bytes)则需按照FB标准封装格式给出每一个数组成员它的偏移量和尾偏移这部分头部(会多占据(成员数+1)*4的额外空间)
下面是FB规范了尾部1字节的类型的常量值
|
类型 |
值 |
|
char |
-1
(0xFF) |
|
short |
-2
(0xFE) |
|
int |
-4
(0xFC) |
|
int64 |
-8
(0xF8) |
|
uchar |
1 |
|
ushort |
2 |
|
uint |
4 |
|
bool |
1 |
|
float |
‘f’
(0x66) |
|
double |
‘d’
(0x64) |
|
String |
‘s’
(0x73) |
|
Bytes |
‘b’
(0x62) |
注:String和Bytes更多只是个示意实践中直接根据语言中的声明类型直接判断而无需理会,或者动态语言随意声明一个空数组[],由封包中的最后一个字节类型得知解析并加入正确类型值到数组中!